Discrete Mathematics With Applications 4th Edition Chapter Overview
Two-dimensional array of numbers with specific operations
For other uses, see Matrix.

An m × n matrix: the m rows are horizontal and the n columns are vertical. Each element of a matrix is often denoted by a variable with two subscripts. For example, a 2,1 represents the element at the second row and first column of the matrix.
In mathematics, a matrix (plural matrices) is a rectangular array or table of numbers, symbols, or expressions, arranged in rows and columns, which is used to represent a mathematical object or a property of such an object.
For example,

is a matrix with two rows and three columns; one say often a "two by three matrix", a "2×3-matrix", or a matrix of dimension 2×3.
Without further specifications, matrices represent linear maps, and allow explicit computations in linear algebra. Therefore, the study of matrices is a large part of linear algebra, and most properties and operations of abstract linear algebra can be expressed in terms of matrices. For example, matrix multiplication represents composition of linear maps.
Not all matrices are related to linear algebra. This is, in particular, the case in graph theory, of incidence matrices, and adjacency matrices.[1] This article focuses on matrices related to linear algebra, and, unless otherwise specified, all matrices represent linear maps or may be viewed as such.
Square matrices, matrices with the same number of rows and columns, play a major role in matrix theory. Square matrices of a given dimension form a noncommutative ring, which is one of the most common examples of a noncommutative ring. The determinant of a square matrix is a number associated to the matrix, which is fundamental for the study of a square matrix; for example, a square matrix is invertible if and only if it has a nonzero determinant, and the eigenvalues of a square matrix are the roots of a polynomial determinant.
In geometry, matrices are widely used for specifying and representing geometric transformations (for example rotations) and coordinate changes. In numerical analysis, many computational problems are solved by reducing them to a matrix computation, and this involves often to compute with matrices of huge dimension. Matrices are used in most areas of mathematics and most scientific fields, either directly, or through their use in geometry and numerical analysis.
Definition [edit]
A matrix is a rectangular array of numbers (or other mathematical objects) for which operations such as addition and multiplication are defined.[2] Most commonly, a matrix over a field F is a rectangular array of scalars, each of which is a member of F.[3] [4] A real matrix and a complex matrix are matrices whose entries are respectively real numbers or complex numbers. More general types of entries are discussed below. For instance, this is a real matrix:

The numbers, symbols, or expressions in the matrix are called its entries or its elements. The horizontal and vertical lines of entries in a matrix are called rows and columns, respectively.
Size [edit]
The size of a matrix is defined by the number of rows and columns it contains. There is no limit to the numbers of rows and columns a matrix (in the usual sense) can have as long as they are positive integers. A matrix with m rows and n columns is called an m × n matrix, or m-by-n matrix, while m and n are called its dimensions. For example, the matrix A above is a 3×2 matrix.
Matrices with a single row are called row vectors, and those with a single column are called column vectors. A matrix with the same number of rows and columns is called a square matrix.[5] A matrix with an infinite number of rows or columns (or both) is called an infinite matrix. In some contexts, such as computer algebra programs, it is useful to consider a matrix with no rows or no columns, called an empty matrix.
| Name | Size | Example | Description |
|---|---|---|---|
| Row vector | 1× n | A matrix with one row, sometimes used to represent a vector | |
| Column vector | n ×1 | A matrix with one column, sometimes used to represent a vector | |
| Square matrix | n × n | A matrix with the same number of rows and columns, sometimes used to represent a linear transformation from a vector space to itself, such as reflection, rotation, or shearing. |



Notation [edit]
Matrices are commonly written in box brackets or parentheses:

The specifics of symbolic matrix notation vary widely, with some prevailing trends. Matrices are usually symbolized using upper-case letters (such as A in the examples above), while the corresponding lower-case letters, with two subscript indices (e.g., a 11, or a 1,1), represent the entries. In addition to using upper-case letters to symbolize matrices, many authors use a special typographical style, commonly boldface upright (non-italic), to further distinguish matrices from other mathematical objects. An alternative notation involves the use of a double-underline with the variable name, with or without boldface style (as in the case of ).

The entry in the i-th row and j-th column of a matrix A is sometimes referred to as the i,j, (i,j), or (i,j)th entry of the matrix, and most commonly denoted as a i,j , or aij . Alternative notations for that entry are A[i,j] or A i,j . For example, the (1,3) entry of the following matrix A is 5 (also denoted a 13, a 1,3, A[1,3] or A 1,3):

Sometimes, the entries of a matrix can be defined by a formula such as a i,j = f(i, j). For example, each of the entries of the following matrix A is determined by the formula aij = i − j.

In this case, the matrix itself is sometimes defined by that formula, within square brackets or double parentheses. For example, the matrix above is defined as A = [i−j], or A = ((i−j)). If matrix size is m × n, the above-mentioned formula f(i, j) is valid for any i = 1, ..., m and any j = 1, ..., n. This can be either specified separately, or indicated using m × n as a subscript. For instance, the matrix A above is 3 × 4, and can be defined as A = [i − j] (i = 1, 2, 3; j = 1, ..., 4), or A = [i − j]3×4.
Some programming languages utilize doubly subscripted arrays (or arrays of arrays) to represent an m-×-n matrix. Some programming languages start the numbering of array indexes at zero, in which case the entries of an m-by-n matrix are indexed by 0 ≤ i ≤ m − 1 and 0 ≤ j ≤ n − 1.[6] This article follows the more common convention in mathematical writing where enumeration starts from 1.
An asterisk is occasionally used to refer to whole rows or columns in a matrix. For example, a i,∗ refers to the ith row of A, and a ∗,j refers to the jth column of A.
The set of all m-by-n real matrices is often denoted or The set of all m-by-n matrices matrices over another field or over a ring R, is similarly denoted or If m = n , that is, in the case of square matrices, one does not repeat the dimension: or [7] Often, is used in place of








Basic operations [edit]
| External video | |
|---|---|
| |
There are a number of basic operations that can be applied to modify matrices, called matrix addition, scalar multiplication, transposition, matrix multiplication, row operations, and submatrix.[9]
Addition, scalar multiplication, and transposition [edit]
| Operation | Definition | Example |
|---|---|---|
| Addition | The sum A+B of two m-by-n matrices A and B is calculated entrywise:
|
|
| Scalar multiplication | The product c A of a number c (also called a scalar in the parlance of abstract algebra) and a matrix A is computed by multiplying every entry of A by c:
This operation is called scalar multiplication, but its result is not named "scalar product" to avoid confusion, since "scalar product" is sometimes used as a synonym for "inner product". | |
| Transposition | The transpose of an m-by-n matrix A is the n-by-m matrix A T (also denoted A tr or t A) formed by turning rows into columns and vice versa:
|



Familiar properties of numbers extend to these operations of matrices: for example, addition is commutative, that is, the matrix sum does not depend on the order of the summands: A + B = B + A.[10] The transpose is compatible with addition and scalar multiplication, as expressed by (c A)T = c(A T) and (A + B)T = A T + B T. Finally, (A T)T = A.
Matrix multiplication [edit]

Schematic depiction of the matrix product AB of two matrices A and B.
Multiplication of two matrices is defined if and only if the number of columns of the left matrix is the same as the number of rows of the right matrix. If A is an m-by-n matrix and B is an n-by-p matrix, then their matrix product AB is the m-by-p matrix whose entries are given by dot product of the corresponding row of A and the corresponding column of B:[11]
![{\displaystyle [\mathbf {AB} ]_{i,j}=a_{i,1}b_{1,j}+a_{i,2}b_{2,j}+\cdots +a_{i,n}b_{n,j}=\sum _{r=1}^{n}a_{i,r}b_{r,j},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c903c2c14d249005ce9ebaa47a8d6c6710c1c29e)
where 1 ≤ i ≤ m and 1 ≤ j ≤ p.[12] For example, the underlined entry 2340 in the product is calculated as (2 × 1000) + (3 × 100) + (4 × 10) = 2340:

Matrix multiplication satisfies the rules (AB)C = A(BC) (associativity), and (A + B)C = AC + BC as well as C(A + B) = CA + CB (left and right distributivity), whenever the size of the matrices is such that the various products are defined.[13] The product AB may be defined without BA being defined, namely if A and B are m-by-n and n-by-k matrices, respectively, and m ≠ k. Even if both products are defined, they generally need not be equal, that is:
- AB ≠ BA,
In other words, matrix multiplication is not commutative, in marked contrast to (rational, real, or complex) numbers, whose product is independent of the order of the factors.[11] An example of two matrices not commuting with each other is:

whereas

Besides the ordinary matrix multiplication just described, other less frequently used operations on matrices that can be considered forms of multiplication also exist, such as the Hadamard product and the Kronecker product.[14] They arise in solving matrix equations such as the Sylvester equation.
Row operations [edit]
There are three types of row operations:
- row addition, that is adding a row to another.
- row multiplication, that is multiplying all entries of a row by a non-zero constant;
- row switching, that is interchanging two rows of a matrix;
These operations are used in several ways, including solving linear equations and finding matrix inverses.
Submatrix [edit]
A submatrix of a matrix is obtained by deleting any collection of rows and/or columns.[15] [16] [17] For example, from the following 3-by-4 matrix, we can construct a 2-by-3 submatrix by removing row 3 and column 2:

The minors and cofactors of a matrix are found by computing the determinant of certain submatrices.[17] [18]
A principal submatrix is a square submatrix obtained by removing certain rows and columns. The definition varies from author to author. According to some authors, a principal submatrix is a submatrix in which the set of row indices that remain is the same as the set of column indices that remain.[19] [20] Other authors define a principal submatrix as one in which the first k rows and columns, for some number k, are the ones that remain;[21] this type of submatrix has also been called a leading principal submatrix.[22]
Linear equations [edit]
Matrices can be used to compactly write and work with multiple linear equations, that is, systems of linear equations. For example, if A is an m-by-n matrix, x designates a column vector (that is, n×1-matrix) of n variables x 1, x 2, ..., x n , and b is an m×1-column vector, then the matrix equation

is equivalent to the system of linear equations[23]

Using matrices, this can be solved more compactly than would be possible by writing out all the equations separately. If n = m and the equations are independent, then this can be done by writing

where A −1 is the inverse matrix of A. If A has no inverse, solutions—if any—can be found using its generalized inverse.
Linear transformations [edit]
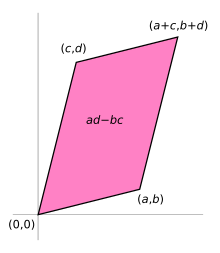
The vectors represented by a 2-by-2 matrix correspond to the sides of a unit square transformed into a parallelogram.
Matrices and matrix multiplication reveal their essential features when related to linear transformations, also known as linear maps. A real m-by-n matrix A gives rise to a linear transformation R n → R m mapping each vector x in R n to the (matrix) product Ax, which is a vector in R m . Conversely, each linear transformation f: R n → R m arises from a unique m-by-n matrix A: explicitly, the (i, j)-entry of A is the i th coordinate of f(e j ), where e j = (0,...,0,1,0,...,0) is the unit vector with 1 in the j th position and 0 elsewhere. The matrix A is said to represent the linear map f, and A is called the transformation matrix of f.
For example, the 2×2 matrix

can be viewed as the transform of the unit square into a parallelogram with vertices at (0, 0), (a, b), (a + c, b + d), and (c, d). The parallelogram pictured at the right is obtained by multiplying A with each of the column vectors , and in turn. These vectors define the vertices of the unit square.


The following table shows several 2×2 real matrices with the associated linear maps of R 2. The blue original is mapped to the green grid and shapes. The origin (0,0) is marked with a black point.
| Horizontal shear with m = 1.25. | Reflection through the vertical axis | Squeeze mapping with r = 3/2 | Scaling by a factor of 3/2 | Rotation by π/6 = 30° |
 |  |  |  |  |





Under the 1-to-1 correspondence between matrices and linear maps, matrix multiplication corresponds to composition of maps:[24] if a k-by-m matrix B represents another linear map g: R m → R k , then the composition g ∘ f is represented by BA since
- (g ∘ f)(x) = g(f(x)) = g(Ax) = B(Ax) = (BA)x.
The last equality follows from the above-mentioned associativity of matrix multiplication.
The rank of a matrix A is the maximum number of linearly independent row vectors of the matrix, which is the same as the maximum number of linearly independent column vectors.[25] Equivalently it is the dimension of the image of the linear map represented by A.[26] The rank–nullity theorem states that the dimension of the kernel of a matrix plus the rank equals the number of columns of the matrix.[27]
Square matrix [edit]
A square matrix is a matrix with the same number of rows and columns.[5] An n-by-n matrix is known as a square matrix of order n. Any two square matrices of the same order can be added and multiplied. The entries a ii form the main diagonal of a square matrix. They lie on the imaginary line that runs from the top left corner to the bottom right corner of the matrix.
Main types [edit]
-
Name Example with n = 3 Diagonal matrix Lower triangular matrix Upper triangular matrix



Diagonal and triangular matrix [edit]
If all entries of A below the main diagonal are zero, A is called an upper triangular matrix. Similarly if all entries of A above the main diagonal are zero, A is called a lower triangular matrix. If all entries outside the main diagonal are zero, A is called a diagonal matrix.
Identity matrix [edit]
The identity matrix I n of size n is the n-by-n matrix in which all the elements on the main diagonal are equal to 1 and all other elements are equal to 0, for example,

It is a square matrix of order n, and also a special kind of diagonal matrix. It is called an identity matrix because multiplication with it leaves a matrix unchanged:
- AI n = I m A = A for any m-by-n matrix A.
A nonzero scalar multiple of an identity matrix is called a scalar matrix. If the matrix entries come from a field, the scalar matrices form a group, under matrix multiplication, that is isomorphic to the multiplicative group of nonzero elements of the field.
Symmetric or skew-symmetric matrix [edit]
A square matrix A that is equal to its transpose, that is, A = A T , is a symmetric matrix. If instead, A is equal to the negative of its transpose, that is, A = −A T, then A is a skew-symmetric matrix. In complex matrices, symmetry is often replaced by the concept of Hermitian matrices, which satisfy A ∗ = A, where the star or asterisk denotes the conjugate transpose of the matrix, that is, the transpose of the complex conjugate of A.
By the spectral theorem, real symmetric matrices and complex Hermitian matrices have an eigenbasis; that is, every vector is expressible as a linear combination of eigenvectors. In both cases, all eigenvalues are real.[28] This theorem can be generalized to infinite-dimensional situations related to matrices with infinitely many rows and columns, see below.
Invertible matrix and its inverse [edit]
A square matrix A is called invertible or non-singular if there exists a matrix B such that
- AB = BA = I n ,[29] [30]
where I n is the n×n identity matrix with 1s on the main diagonal and 0s elsewhere. If B exists, it is unique and is called the inverse matrix of A, denoted A −1.
Definite matrix [edit]
| Positive definite matrix | Indefinite matrix |
|---|---|
| Q(x, y) = 1 / 4 x 2 + y 2 | Q(x, y) = 1 / 4 x 2 − 1/4 y 2 |
 Points such that Q(x,y)=1 (Ellipse). |  Points such that Q(x,y)=1 (Hyperbola). |


A symmetric real matrix A is called positive-definite if the associated quadratic form
- f (x) = x T Ax
has a positive value for every nonzero vector x in R n . If f (x) only yields negative values then A is negative-definite; if f does produce both negative and positive values then A is indefinite.[31] If the quadratic form f yields only non-negative values (positive or zero), the symmetric matrix is called positive-semidefinite (or if only non-positive values, then negative-semidefinite); hence the matrix is indefinite precisely when it is neither positive-semidefinite nor negative-semidefinite.
A symmetric matrix is positive-definite if and only if all its eigenvalues are positive, that is, the matrix is positive-semidefinite and it is invertible.[32] The table at the right shows two possibilities for 2-by-2 matrices.
Allowing as input two different vectors instead yields the bilinear form associated to A :[33]
- B A (x, y) = x T Ay .
In the case of complex matrices, the same terminology and result apply, with symmetric matrix, quadratic form, bilinear form, and transpose x T replaced respectively by Hermitian matrix, Hermitian form, sesquilinear form, and conjugate transpose x H .
Orthogonal matrix [edit]
An orthogonal matrix is a square matrix with real entries whose columns and rows are orthogonal unit vectors (that is, orthonormal vectors). Equivalently, a matrix A is orthogonal if its transpose is equal to its inverse:

which entails

where I n is the identity matrix of size n.
An orthogonal matrix A is necessarily invertible (with inverse A −1 = A T ), unitary ( A −1 = A*), and normal ( A*A = AA*). The determinant of any orthogonal matrix is either +1 or −1. A special orthogonal matrix is an orthogonal matrix with determinant +1. As a linear transformation, every orthogonal matrix with determinant +1 is a pure rotation without reflection, i.e., the transformation preserves the orientation of the transformed structure, while every orthogonal matrix with determinant -1 reverses the orientation, i.e., is a composition of a pure reflection and a (possibly null) rotation. The identity matrices have determinant 1, and are pure rotations by an angle zero.
The complex analogue of an orthogonal matrix is a unitary matrix.
Main operations [edit]
Trace [edit]
The trace, tr(A) of a square matrix A is the sum of its diagonal entries. While matrix multiplication is not commutative as mentioned above, the trace of the product of two matrices is independent of the order of the factors:
- tr(AB) = tr(BA).
This is immediate from the definition of matrix multiplication:

It follows that the trace of the product of more than two matrices is independent of cyclic permutations of the matrices, however this does not in general apply for arbitrary permutations (for example, tr(ABC) ≠ tr(BAC), in general). Also, the trace of a matrix is equal to that of its transpose, that is,
- tr(A) = tr(A T).
Determinant [edit]

A linear transformation on R 2 given by the indicated matrix. The determinant of this matrix is −1, as the area of the green parallelogram at the right is 1, but the map reverses the orientation, since it turns the counterclockwise orientation of the vectors to a clockwise one.
The determinant of a square matrix A (denoted det(A) or |A|) is a number encoding certain properties of the matrix. A matrix is invertible if and only if its determinant is nonzero. Its absolute value equals the area (in R 2) or volume (in R 3) of the image of the unit square (or cube), while its sign corresponds to the orientation of the corresponding linear map: the determinant is positive if and only if the orientation is preserved.
The determinant of 2-by-2 matrices is given by
- [34]

The determinant of 3-by-3 matrices involves 6 terms (rule of Sarrus). The more lengthy Leibniz formula generalises these two formulae to all dimensions.[35]
The determinant of a product of square matrices equals the product of their determinants:
- det(AB) = det(A) · det(B).[36]
Adding a multiple of any row to another row, or a multiple of any column to another column does not change the determinant. Interchanging two rows or two columns affects the determinant by multiplying it by −1.[37] Using these operations, any matrix can be transformed to a lower (or upper) triangular matrix, and for such matrices, the determinant equals the product of the entries on the main diagonal; this provides a method to calculate the determinant of any matrix. Finally, the Laplace expansion expresses the determinant in terms of minors, that is, determinants of smaller matrices.[38] This expansion can be used for a recursive definition of determinants (taking as starting case the determinant of a 1-by-1 matrix, which is its unique entry, or even the determinant of a 0-by-0 matrix, which is 1), that can be seen to be equivalent to the Leibniz formula. Determinants can be used to solve linear systems using Cramer's rule, where the division of the determinants of two related square matrices equates to the value of each of the system's variables.[39]
Eigenvalues and eigenvectors [edit]
A number λ and a non-zero vector v satisfying

are called an eigenvalue and an eigenvector of A, respectively.[40] [41] The number λ is an eigenvalue of an n×n-matrix A if and only if A−λI n is not invertible, which is equivalent to
- [42]

The polynomial p A in an indeterminate X given by evaluation of the determinant det(X I n −A) is called the characteristic polynomial of A. It is a monic polynomial of degree n. Therefore the polynomial equation p A (λ)=0 has at most n different solutions, that is, eigenvalues of the matrix.[43] They may be complex even if the entries of A are real. According to the Cayley–Hamilton theorem, p A (A) = 0 , that is, the result of substituting the matrix itself into its own characteristic polynomial yields the zero matrix.
Computational aspects [edit]
Matrix calculations can be often performed with different techniques. Many problems can be solved by both direct algorithms or iterative approaches. For example, the eigenvectors of a square matrix can be obtained by finding a sequence of vectors x n converging to an eigenvector when n tends to infinity.[44]
To choose the most appropriate algorithm for each specific problem, it is important to determine both the effectiveness and precision of all the available algorithms. The domain studying these matters is called numerical linear algebra.[45] As with other numerical situations, two main aspects are the complexity of algorithms and their numerical stability.
Determining the complexity of an algorithm means finding upper bounds or estimates of how many elementary operations such as additions and multiplications of scalars are necessary to perform some algorithm, for example, multiplication of matrices. Calculating the matrix product of two n-by-n matrices using the definition given above needs n 3 multiplications, since for any of the n 2 entries of the product, n multiplications are necessary. The Strassen algorithm outperforms this "naive" algorithm; it needs only n 2.807 multiplications.[46] A refined approach also incorporates specific features of the computing devices.
In many practical situations additional information about the matrices involved is known. An important case are sparse matrices, that is, matrices most of whose entries are zero. There are specifically adapted algorithms for, say, solving linear systems Ax = b for sparse matrices A, such as the conjugate gradient method.[47]
An algorithm is, roughly speaking, numerically stable, if little deviations in the input values do not lead to big deviations in the result. For example, calculating the inverse of a matrix via Laplace expansion (adj(A) denotes the adjugate matrix of A)
- A −1 = adj(A) / det(A)
may lead to significant rounding errors if the determinant of the matrix is very small. The norm of a matrix can be used to capture the conditioning of linear algebraic problems, such as computing a matrix's inverse.[48]
Most computer programming languages support arrays but are not designed with built-in commands for matrices. Instead, available external libraries provide matrix operations on arrays, in nearly all currently used programming languages. Matrix manipulation was among the earliest numerical applications of computers.[49] The original Dartmouth BASIC had built-in commands for matrix arithmetic on arrays from its second edition implementation in 1964. As early as the 1970s, some engineering desktop computers such as the HP 9830 had ROM cartridges to add BASIC commands for matrices. Some computer languages such as APL were designed to manipulate matrices, and various mathematical programs can be used to aid computing with matrices.[50]
Decomposition [edit]
There are several methods to render matrices into a more easily accessible form. They are generally referred to as matrix decomposition or matrix factorization techniques. The interest of all these techniques is that they preserve certain properties of the matrices in question, such as determinant, rank, or inverse, so that these quantities can be calculated after applying the transformation, or that certain matrix operations are algorithmically easier to carry out for some types of matrices.
The LU decomposition factors matrices as a product of lower (L) and an upper triangular matrices (U).[51] Once this decomposition is calculated, linear systems can be solved more efficiently, by a simple technique called forward and back substitution. Likewise, inverses of triangular matrices are algorithmically easier to calculate. The Gaussian elimination is a similar algorithm; it transforms any matrix to row echelon form.[52] Both methods proceed by multiplying the matrix by suitable elementary matrices, which correspond to permuting rows or columns and adding multiples of one row to another row. Singular value decomposition expresses any matrix A as a product UDV ∗, where U and V are unitary matrices and D is a diagonal matrix.
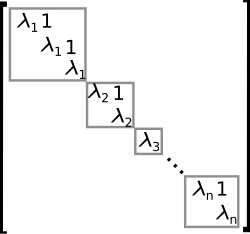
An example of a matrix in Jordan normal form. The grey blocks are called Jordan blocks.
The eigendecomposition or diagonalization expresses A as a product VDV −1, where D is a diagonal matrix and V is a suitable invertible matrix.[53] If A can be written in this form, it is called diagonalizable. More generally, and applicable to all matrices, the Jordan decomposition transforms a matrix into Jordan normal form, that is to say matrices whose only nonzero entries are the eigenvalues λ1 to λn of A, placed on the main diagonal and possibly entries equal to one directly above the main diagonal, as shown at the right.[54] Given the eigendecomposition, the n th power of A (that is, n-fold iterated matrix multiplication) can be calculated via
- A n = (VDV −1) n = VDV −1 VDV −1...VDV −1 = VD n V −1
and the power of a diagonal matrix can be calculated by taking the corresponding powers of the diagonal entries, which is much easier than doing the exponentiation for A instead. This can be used to compute the matrix exponential e A , a need frequently arising in solving linear differential equations, matrix logarithms and square roots of matrices.[55] To avoid numerically ill-conditioned situations, further algorithms such as the Schur decomposition can be employed.[56]
Abstract algebraic aspects and generalizations [edit]
Matrices can be generalized in different ways. Abstract algebra uses matrices with entries in more general fields or even rings, while linear algebra codifies properties of matrices in the notion of linear maps. It is possible to consider matrices with infinitely many columns and rows. Another extension is tensors, which can be seen as higher-dimensional arrays of numbers, as opposed to vectors, which can often be realized as sequences of numbers, while matrices are rectangular or two-dimensional arrays of numbers.[57] Matrices, subject to certain requirements tend to form groups known as matrix groups. Similarly under certain conditions matrices form rings known as matrix rings. Though the product of matrices is not in general commutative yet certain matrices form fields known as matrix fields.
Matrices with more general entries [edit]
This article focuses on matrices whose entries are real or complex numbers. However, matrices can be considered with much more general types of entries than real or complex numbers. As a first step of generalization, any field, that is, a set where addition, subtraction, multiplication, and division operations are defined and well-behaved, may be used instead of R or C, for example rational numbers or finite fields. For example, coding theory makes use of matrices over finite fields. Wherever eigenvalues are considered, as these are roots of a polynomial they may exist only in a larger field than that of the entries of the matrix; for instance, they may be complex in the case of a matrix with real entries. The possibility to reinterpret the entries of a matrix as elements of a larger field (for example, to view a real matrix as a complex matrix whose entries happen to be all real) then allows considering each square matrix to possess a full set of eigenvalues. Alternatively one can consider only matrices with entries in an algebraically closed field, such as C, from the outset.
More generally, matrices with entries in a ring R are widely used in mathematics.[58] Rings are a more general notion than fields in that a division operation need not exist. The very same addition and multiplication operations of matrices extend to this setting, too. The set M(n, R) (also denoted M n (R)[7]) of all square n-by-n matrices over R is a ring called matrix ring, isomorphic to the endomorphism ring of the left R-module R n .[59] If the ring R is commutative, that is, its multiplication is commutative, then M(n, R) is a unitary noncommutative (unless n = 1) associative algebra over R. The determinant of square matrices over a commutative ring R can still be defined using the Leibniz formula; such a matrix is invertible if and only if its determinant is invertible in R, generalising the situation over a field F, where every nonzero element is invertible.[60] Matrices over superrings are called supermatrices.[61]
Matrices do not always have all their entries in the same ring– or even in any ring at all. One special but common case is block matrices, which may be considered as matrices whose entries themselves are matrices. The entries need not be square matrices, and thus need not be members of any ring; but their sizes must fulfill certain compatibility conditions.
Relationship to linear maps [edit]
Linear maps R n → R m are equivalent to m-by-n matrices, as described above. More generally, any linear map f: V → W between finite-dimensional vector spaces can be described by a matrix A = (a ij ), after choosing bases v 1, ..., v n of V, and w 1, ..., w m of W (so n is the dimension of V and m is the dimension of W), which is such that

In other words, column j of A expresses the image of v j in terms of the basis vectors w i of W; thus this relation uniquely determines the entries of the matrix A. The matrix depends on the choice of the bases: different choices of bases give rise to different, but equivalent matrices.[62] Many of the above concrete notions can be reinterpreted in this light, for example, the transpose matrix A T describes the transpose of the linear map given by A, with respect to the dual bases.[63]
These properties can be restated more naturally: the category of all matrices with entries in a field with multiplication as composition is equivalent to the category of finite-dimensional vector spaces and linear maps over this field.

More generally, the set of m×n matrices can be used to represent the R-linear maps between the free modules R m and R n for an arbitrary ring R with unity. When n = m composition of these maps is possible, and this gives rise to the matrix ring of n×n matrices representing the endomorphism ring of R n .
Matrix groups [edit]
A group is a mathematical structure consisting of a set of objects together with a binary operation, that is, an operation combining any two objects to a third, subject to certain requirements.[64] A group in which the objects are matrices and the group operation is matrix multiplication is called a matrix group.[65] [66] Since a group every element must be invertible, the most general matrix groups are the groups of all invertible matrices of a given size, called the general linear groups.
Any property of matrices that is preserved under matrix products and inverses can be used to define further matrix groups. For example, matrices with a given size and with a determinant of 1 form a subgroup of (that is, a smaller group contained in) their general linear group, called a special linear group.[67] Orthogonal matrices, determined by the condition
- M T M = I,
form the orthogonal group.[68] Every orthogonal matrix has determinant 1 or −1. Orthogonal matrices with determinant 1 form a subgroup called special orthogonal group.
Every finite group is isomorphic to a matrix group, as one can see by considering the regular representation of the symmetric group.[69] General groups can be studied using matrix groups, which are comparatively well understood, by means of representation theory.[70]
Infinite matrices [edit]
It is also possible to consider matrices with infinitely many rows and/or columns[71] even if, being infinite objects, one cannot write down such matrices explicitly. All that matters is that for every element in the set indexing rows, and every element in the set indexing columns, there is a well-defined entry (these index sets need not even be subsets of the natural numbers). The basic operations of addition, subtraction, scalar multiplication, and transposition can still be defined without problem; however matrix multiplication may involve infinite summations to define the resulting entries, and these are not defined in general.
If R is any ring with unity, then the ring of endomorphisms of as a right R module is isomorphic to the ring of column finite matrices whose entries are indexed by , and whose columns each contain only finitely many nonzero entries. The endomorphisms of M considered as a left R module result in an analogous object, the row finite matrices whose rows each only have finitely many nonzero entries.




If infinite matrices are used to describe linear maps, then only those matrices can be used all of whose columns have but a finite number of nonzero entries, for the following reason. For a matrix A to describe a linear map f: V→W, bases for both spaces must have been chosen; recall that by definition this means that every vector in the space can be written uniquely as a (finite) linear combination of basis vectors, so that written as a (column) vector v of coefficients, only finitely many entries v i are nonzero. Now the columns of A describe the images by f of individual basis vectors of V in the basis of W, which is only meaningful if these columns have only finitely many nonzero entries. There is no restriction on the rows of A however: in the product A·v there are only finitely many nonzero coefficients of v involved, so every one of its entries, even if it is given as an infinite sum of products, involves only finitely many nonzero terms and is therefore well defined. Moreover, this amounts to forming a linear combination of the columns of A that effectively involves only finitely many of them, whence the result has only finitely many nonzero entries because each of those columns does. Products of two matrices of the given type are well defined (provided that the column-index and row-index sets match), are of the same type, and correspond to the composition of linear maps.
If R is a normed ring, then the condition of row or column finiteness can be relaxed. With the norm in place, absolutely convergent series can be used instead of finite sums. For example, the matrices whose column sums are absolutely convergent sequences form a ring. Analogously, the matrices whose row sums are absolutely convergent series also form a ring.
Infinite matrices can also be used to describe operators on Hilbert spaces, where convergence and continuity questions arise, which again results in certain constraints that must be imposed. However, the explicit point of view of matrices tends to obfuscate the matter,[72] and the abstract and more powerful tools of functional analysis can be used instead.
Empty matrix [edit]
An empty matrix is a matrix in which the number of rows or columns (or both) is zero.[73] [74] Empty matrices help dealing with maps involving the zero vector space. For example, if A is a 3-by-0 matrix and B is a 0-by-3 matrix, then AB is the 3-by-3 zero matrix corresponding to the null map from a 3-dimensional space V to itself, while BA is a 0-by-0 matrix. There is no common notation for empty matrices, but most computer algebra systems allow creating and computing with them. The determinant of the 0-by-0 matrix is 1 as follows regarding the empty product occurring in the Leibniz formula for the determinant as 1. This value is also consistent with the fact that the identity map from any finite-dimensional space to itself has determinant1, a fact that is often used as a part of the characterization of determinants.
Applications [edit]
There are numerous applications of matrices, both in mathematics and other sciences. Some of them merely take advantage of the compact representation of a set of numbers in a matrix. For example, in game theory and economics, the payoff matrix encodes the payoff for two players, depending on which out of a given (finite) set of alternatives the players choose.[75] Text mining and automated thesaurus compilation makes use of document-term matrices such as tf-idf to track frequencies of certain words in several documents.[76]
Complex numbers can be represented by particular real 2-by-2 matrices via

under which addition and multiplication of complex numbers and matrices correspond to each other. For example, 2-by-2 rotation matrices represent the multiplication with some complex number of absolute value 1, as above. A similar interpretation is possible for quaternions[77] and Clifford algebras in general.
Early encryption techniques such as the Hill cipher also used matrices. However, due to the linear nature of matrices, these codes are comparatively easy to break.[78] Computer graphics uses matrices both to represent objects and to calculate transformations of objects using affine rotation matrices to accomplish tasks such as projecting a three-dimensional object onto a two-dimensional screen, corresponding to a theoretical camera observation.[79] Matrices over a polynomial ring are important in the study of control theory.
Chemistry makes use of matrices in various ways, particularly since the use of quantum theory to discuss molecular bonding and spectroscopy. Examples are the overlap matrix and the Fock matrix used in solving the Roothaan equations to obtain the molecular orbitals of the Hartree–Fock method.
Graph theory [edit]

An undirected graph with adjacency matrix:

The adjacency matrix of a finite graph is a basic notion of graph theory.[80] It records which vertices of the graph are connected by an edge. Matrices containing just two different values (1 and 0 meaning for example "yes" and "no", respectively) are called logical matrices. The distance (or cost) matrix contains information about distances of the edges.[81] These concepts can be applied to websites connected by hyperlinks or cities connected by roads etc., in which case (unless the connection network is extremely dense) the matrices tend to be sparse, that is, contain few nonzero entries. Therefore, specifically tailored matrix algorithms can be used in network theory.
Analysis and geometry [edit]
The Hessian matrix of a differentiable function ƒ: R n → R consists of the second derivatives of ƒ with respect to the several coordinate directions, that is,[82]
![H(f)=\left[{\frac {\partial ^{2}f}{\partial x_{i}\,\partial x_{j}}}\right].](https://wikimedia.org/api/rest_v1/media/math/render/svg/9cf91a060a82dd7a47c305e9a4c2865378fcf35f)

At the saddle point (x =0, y =0) (red) of the function f(x,−y) = x 2 − y 2, the Hessian matrix is indefinite.

It encodes information about the local growth behaviour of the function: given a critical point x =(x 1,..., x n ), that is, a point where the first partial derivatives of ƒ vanish, the function has a local minimum if the Hessian matrix is positive definite. Quadratic programming can be used to find global minima or maxima of quadratic functions closely related to the ones attached to matrices (see above).[83]

Another matrix frequently used in geometrical situations is the Jacobi matrix of a differentiable map f: R n → R m . If f 1, ..., f m denote the components of f, then the Jacobi matrix is defined as[84]
![J(f)=\left[{\frac {\partial f_{i}}{\partial x_{j}}}\right]_{1\leq i\leq m,1\leq j\leq n}.](https://wikimedia.org/api/rest_v1/media/math/render/svg/bdbd42114b895c82930ea1e229b566f71fd6b07d)
If n > m, and if the rank of the Jacobi matrix attains its maximal value m, f is locally invertible at that point, by the implicit function theorem.[85]
Partial differential equations can be classified by considering the matrix of coefficients of the highest-order differential operators of the equation. For elliptic partial differential equations this matrix is positive definite, which has a decisive influence on the set of possible solutions of the equation in question.[86]
The finite element method is an important numerical method to solve partial differential equations, widely applied in simulating complex physical systems. It attempts to approximate the solution to some equation by piecewise linear functions, where the pieces are chosen concerning a sufficiently fine grid, which in turn can be recast as a matrix equation.[87]
Probability theory and statistics [edit]
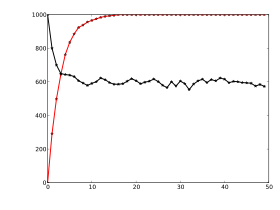
Two different Markov chains. The chart depicts the number of particles (of a total of 1000) in state "2". Both limiting values can be determined from the transition matrices, which are given by (red) and (black).


Stochastic matrices are square matrices whose rows are probability vectors, that is, whose entries are non-negative and sum up to one. Stochastic matrices are used to define Markov chains with finitely many states.[88] A row of the stochastic matrix gives the probability distribution for the next position of some particle currently in the state that corresponds to the row. Properties of the Markov chain-like absorbing states, that is, states that any particle attains eventually, can be read off the eigenvectors of the transition matrices.[89]
Statistics also makes use of matrices in many different forms.[90] Descriptive statistics is concerned with describing data sets, which can often be represented as data matrices, which may then be subjected to dimensionality reduction techniques. The covariance matrix encodes the mutual variance of several random variables.[91] Another technique using matrices are linear least squares, a method that approximates a finite set of pairs (x 1, y 1), (x 2, y 2), ..., (x N , y N ), by a linear function
- y i ≈ ax i + b, i = 1, ..., N
which can be formulated in terms of matrices, related to the singular value decomposition of matrices.[92]
Random matrices are matrices whose entries are random numbers, subject to suitable probability distributions, such as matrix normal distribution. Beyond probability theory, they are applied in domains ranging from number theory to physics.[93] [94]
Symmetries and transformations in physics [edit]
Linear transformations and the associated symmetries play a key role in modern physics. For example, elementary particles in quantum field theory are classified as representations of the Lorentz group of special relativity and, more specifically, by their behavior under the spin group. Concrete representations involving the Pauli matrices and more general gamma matrices are an integral part of the physical description of fermions, which behave as spinors.[95] For the three lightest quarks, there is a group-theoretical representation involving the special unitary group SU(3); for their calculations, physicists use a convenient matrix representation known as the Gell-Mann matrices, which are also used for the SU(3) gauge group that forms the basis of the modern description of strong nuclear interactions, quantum chromodynamics. The Cabibbo–Kobayashi–Maskawa matrix, in turn, expresses the fact that the basic quark states that are important for weak interactions are not the same as, but linearly related to the basic quark states that define particles with specific and distinct masses.[96]
Linear combinations of quantum states [edit]
The first model of quantum mechanics (Heisenberg, 1925) represented the theory's operators by infinite-dimensional matrices acting on quantum states.[97] This is also referred to as matrix mechanics. One particular example is the density matrix that characterizes the "mixed" state of a quantum system as a linear combination of elementary, "pure" eigenstates.[98]
Another matrix serves as a key tool for describing the scattering experiments that form the cornerstone of experimental particle physics: Collision reactions such as occur in particle accelerators, where non-interacting particles head towards each other and collide in a small interaction zone, with a new set of non-interacting particles as the result, can be described as the scalar product of outgoing particle states and a linear combination of ingoing particle states. The linear combination is given by a matrix known as the S-matrix, which encodes all information about the possible interactions between particles.[99]
Normal modes [edit]
A general application of matrices in physics is the description of linearly coupled harmonic systems. The equations of motion of such systems can be described in matrix form, with a mass matrix multiplying a generalized velocity to give the kinetic term, and a force matrix multiplying a displacement vector to characterize the interactions. The best way to obtain solutions is to determine the system's eigenvectors, its normal modes, by diagonalizing the matrix equation. Techniques like this are crucial when it comes to the internal dynamics of molecules: the internal vibrations of systems consisting of mutually bound component atoms.[100] They are also needed for describing mechanical vibrations, and oscillations in electrical circuits.[101]
Geometrical optics [edit]
Geometrical optics provides further matrix applications. In this approximative theory, the wave nature of light is neglected. The result is a model in which light rays are indeed geometrical rays. If the deflection of light rays by optical elements is small, the action of a lens or reflective element on a given light ray can be expressed as multiplication of a two-component vector with a two-by-two matrix called ray transfer matrix analysis: the vector's components are the light ray's slope and its distance from the optical axis, while the matrix encodes the properties of the optical element. Actually, there are two kinds of matrices, viz. a refraction matrix describing the refraction at a lens surface, and a translation matrix, describing the translation of the plane of reference to the next refracting surface, where another refraction matrix applies. The optical system, consisting of a combination of lenses and/or reflective elements, is simply described by the matrix resulting from the product of the components' matrices.[102]
Electronics [edit]
Traditional mesh analysis and nodal analysis in electronics lead to a system of linear equations that can be described with a matrix.
The behaviour of many electronic components can be described using matrices. Let A be a 2-dimensional vector with the component's input voltage v 1 and input current i 1 as its elements, and let B be a 2-dimensional vector with the component's output voltage v 2 and output current i 2 as its elements. Then the behaviour of the electronic component can be described by B = H · A, where H is a 2 x 2 matrix containing one impedance element (h 12), one admittance element (h 21), and two dimensionless elements (h 11 and h 22). Calculating a circuit now reduces to multiplying matrices.
History [edit]
Matrices have a long history of application in solving linear equations but they were known as arrays until the 1800s. The Chinese text The Nine Chapters on the Mathematical Art written in 10th–2nd century BCE is the first example of the use of array methods to solve simultaneous equations,[103] including the concept of determinants. In 1545 Italian mathematician Gerolamo Cardano introduced the method to Europe when he published Ars Magna.[104] The Japanese mathematician Seki used the same array methods to solve simultaneous equations in 1683.[105] The Dutch mathematician Jan de Witt represented transformations using arrays in his 1659 book Elements of Curves (1659).[106] Between 1700 and 1710 Gottfried Wilhelm Leibniz publicized the use of arrays for recording information or solutions and experimented with over 50 different systems of arrays.[104] Cramer presented his rule in 1750.
The term "matrix" (Latin for "womb", derived from mater—mother[107]) was coined by James Joseph Sylvester in 1850,[108] who understood a matrix as an object giving rise to several determinants today called minors, that is to say, determinants of smaller matrices that derive from the original one by removing columns and rows. In an 1851 paper, Sylvester explains:
- I have in previous papers defined a "Matrix" as a rectangular array of terms, out of which different systems of determinants may be engendered as from the womb of a common parent.[109]
Arthur Cayley published a treatise on geometric transformations using matrices that were not rotated versions of the coefficients being investigated as had previously been done. Instead, he defined operations such as addition, subtraction, multiplication, and division as transformations of those matrices and showed the associative and distributive properties held true. Cayley investigated and demonstrated the non-commutative property of matrix multiplication as well as the commutative property of matrix addition.[104] Early matrix theory had limited the use of arrays almost exclusively to determinants and Arthur Cayley's abstract matrix operations were revolutionary. He was instrumental in proposing a matrix concept independent of equation systems. In 1858 Cayley published his A memoir on the theory of matrices [110] [111] in which he proposed and demonstrated the Cayley–Hamilton theorem.[104]
The English mathematician Cuthbert Edmund Cullis was the first to use modern bracket notation for matrices in 1913 and he simultaneously demonstrated the first significant use of the notation A = [a i,j ] to represent a matrix where a i,j refers to the ith row and the jth column.[104]
The modern study of determinants sprang from several sources.[112] Number-theoretical problems led Gauss to relate coefficients of quadratic forms, that is, expressions such as x 2 + xy − 2y 2, and linear maps in three dimensions to matrices. Eisenstein further developed these notions, including the remark that, in modern parlance, matrix products are non-commutative. Cauchy was the first to prove general statements about determinants, using as definition of the determinant of a matrix A = [a i,j ] the following: replace the powers a j k by a jk in the polynomial
- ,

where Π denotes the product of the indicated terms. He also showed, in 1829, that the eigenvalues of symmetric matrices are real.[113] Jacobi studied "functional determinants"—later called Jacobi determinants by Sylvester—which can be used to describe geometric transformations at a local (or infinitesimal) level, see above; Kronecker's Vorlesungen über die Theorie der Determinanten [114] and Weierstrass' Zur Determinantentheorie,[115] both published in 1903, first treated determinants axiomatically, as opposed to previous more concrete approaches such as the mentioned formula of Cauchy. At that point, determinants were firmly established.
Many theorems were first established for small matrices only, for example, the Cayley–Hamilton theorem was proved for 2×2 matrices by Cayley in the aforementioned memoir, and by Hamilton for 4×4 matrices. Frobenius, working on bilinear forms, generalized the theorem to all dimensions (1898). Also at the end of the 19th century, the Gauss–Jordan elimination (generalizing a special case now known as Gauss elimination) was established by Jordan. In the early 20th century, matrices attained a central role in linear algebra,[116] partially due to their use in classification of the hypercomplex number systems of the previous century.
The inception of matrix mechanics by Heisenberg, Born and Jordan led to studying matrices with infinitely many rows and columns.[117] Later, von Neumann carried out the mathematical formulation of quantum mechanics, by further developing functional analytic notions such as linear operators on Hilbert spaces, which, very roughly speaking, correspond to Euclidean space, but with an infinity of independent directions.
Other historical usages of the word "matrix" in mathematics [edit]
The word has been used in unusual ways by at least two authors of historical importance.
Bertrand Russell and Alfred North Whitehead in their Principia Mathematica (1910–1913) use the word "matrix" in the context of their axiom of reducibility. They proposed this axiom as a means to reduce any function to one of lower type, successively, so that at the "bottom" (0 order) the function is identical to its extension:
- "Let us give the name of matrix to any function, of however many variables, that does not involve any apparent variables. Then, any possible function other than a matrix derives from a matrix by means of generalization, that is, by considering the proposition that the function in question is true with all possible values or with some value of one of the arguments, the other argument or arguments remaining undetermined".[118]
For example, a function Φ(x, y) of two variables x and y can be reduced to a collection of functions of a single variable, for example, y, by "considering" the function for all possible values of "individuals" ai substituted in place of variable x. And then the resulting collection of functions of the single variable y, that is, ∀ai: Φ(ai, y), can be reduced to a "matrix" of values by "considering" the function for all possible values of "individuals" bi substituted in place of variable y:
- ∀bj∀ai: Φ(ai, bj ).
Alfred Tarski in his 1946 Introduction to Logic used the word "matrix" synonymously with the notion of truth table as used in mathematical logic.[119]
See also [edit]
- List of named matrices
- Algebraic multiplicity – Multiplicity of an eigenvalue as a root of the characteristic polynomial
- Geometric multiplicity – Dimension of the eigenspace associated with an eigenvalue
- Gram–Schmidt process – Method for orthonormalizing a set of vectors
- Irregular matrix
- Matrix calculus – Specialized notation for multivariable calculus
- Matrix function
- Matrix multiplication algorithm
- Tensor — A generalization of matrices with any number of indices
Notes [edit]
- ^ However, in the case of adjacency matrices, matrix multiplication or a variant of it allows the simultaneous computation of the number of paths between any two vertices, and of the shortest length of a path between two vertices.
- ^ Lang 2002
- ^ Fraleigh (1976, p. 209)
- ^ Nering (1970, p. 37)
- ^ a b Weisstein, Eric W. "Matrix". mathworld.wolfram.com . Retrieved 2020-08-19 .
- ^ Oualline 2003, Ch. 5
- ^ a b Pop; Furdui (2017). Square Matrices of Order 2. Springer International Publishing. ISBN978-3-319-54938-5.
- ^ "How to organize, add and multiply matrices - Bill Shillito". TED ED. Retrieved April 6, 2013.
- ^ Brown 1991, Definition I.2.1 (addition), Definition I.2.4 (scalar multiplication), and Definition I.2.33 (transpose)
- ^ Brown 1991, Theorem I.2.6
- ^ a b "How to Multiply Matrices". www.mathsisfun.com . Retrieved 2020-08-19 .
- ^ Brown 1991, Definition I.2.20
- ^ Brown 1991, Theorem I.2.24
- ^ Horn & Johnson 1985, Ch. 4 and 5
- ^ Bronson (1970, p. 16)
- ^ Kreyszig (1972, p. 220)
- ^ a b Protter & Morrey (1970, p. 869) harvtxt error: no target: CITEREFProtterMorrey1970 (help)
- ^ Kreyszig (1972, pp. 241, 244)
- ^ Schneider, Hans; Barker, George Phillip (2012), Matrices and Linear Algebra, Dover Books on Mathematics, Courier Dover Corporation, p. 251, ISBN978-0-486-13930-2 .
- ^ Perlis, Sam (1991), Theory of Matrices, Dover books on advanced mathematics, Courier Dover Corporation, p. 103, ISBN978-0-486-66810-9 .
- ^ Anton, Howard (2010), Elementary Linear Algebra (10th ed.), John Wiley & Sons, p. 414, ISBN978-0-470-45821-1 .
- ^ Horn, Roger A.; Johnson, Charles R. (2012), Matrix Analysis (2nd ed.), Cambridge University Press, p. 17, ISBN978-0-521-83940-2 .
- ^ Brown 1991, I.2.21 and 22
- ^ Greub 1975, Section III.2
- ^ Brown 1991, Definition II.3.3
- ^ Greub 1975, Section III.1
- ^ Brown 1991, Theorem II.3.22
- ^ Horn & Johnson 1985, Theorem 2.5.6
- ^ Brown 1991, Definition I.2.28
- ^ Brown 1991, Definition I.5.13
- ^ Horn & Johnson 1985, Chapter 7
- ^ Horn & Johnson 1985, Theorem 7.2.1
- ^ Horn & Johnson 1985, Example 4.0.6, p. 169
- ^ "Matrix | mathematics". Encyclopedia Britannica . Retrieved 2020-08-19 .
- ^ Brown 1991, Definition III.2.1
- ^ Brown 1991, Theorem III.2.12
- ^ Brown 1991, Corollary III.2.16
- ^ Mirsky 1990, Theorem 1.4.1
- ^ Brown 1991, Theorem III.3.18
- ^ Eigen means "own" in German and in Dutch.
- ^ Brown 1991, Definition III.4.1
- ^ Brown 1991, Definition III.4.9
- ^ Brown 1991, Corollary III.4.10
- ^ Householder 1975, Ch. 7
- ^ Bau III & Trefethen 1997
- ^ Golub & Van Loan 1996, Algorithm 1.3.1
- ^ Golub & Van Loan 1996, Chapters 9 and 10, esp. section 10.2
- ^ Golub & Van Loan 1996, Chapter 2.3
- ^ Grcar, Joseph F. (2011-01-01). "John von Neumann's Analysis of Gaussian Elimination and the Origins of Modern Numerical Analysis". SIAM Review. 53 (4): 607–682. doi:10.1137/080734716. ISSN 0036-1445.
- ^ For example, Mathematica, see Wolfram 2003, Ch. 3.7
- ^ Press, Flannery & Teukolsky 1992
- ^ Stoer & Bulirsch 2002, Section 4.1
- ^ Horn & Johnson 1985, Theorem 2.5.4
- ^ Horn & Johnson 1985, Ch. 3.1, 3.2
- ^ Arnold & Cooke 1992, Sections 14.5, 7, 8
- ^ Bronson 1989, Ch. 15
- ^ Coburn 1955, Ch. V
- ^ Lang 2002, Chapter XIII
- ^ Lang 2002, XVII.1, p. 643
- ^ Lang 2002, Proposition XIII.4.16
- ^ Reichl 2004, Section L.2
- ^ Greub 1975, Section III.3
- ^ Greub 1975, Section III.3.13
- ^ See any standard reference in a group.
- ^ Additionally, the group must be closed in the general linear group.
- ^ Baker 2003, Def. 1.30
- ^ Baker 2003, Theorem 1.2
- ^ Artin 1991, Chapter 4.5
- ^ Rowen 2008, Example 19.2, p. 198
- ^ See any reference in representation theory or group representation.
- ^ See the item "Matrix" in Itõ, ed. 1987
- ^ "Not much of matrix theory carries over to infinite-dimensional spaces, and what does is not so useful, but it sometimes helps." Halmos 1982, p. 23, Chapter 5
- ^ "Empty Matrix: A matrix is empty if either its row or column dimension is zero", Glossary Archived 2009-04-29 at the Wayback Machine, O-Matrix v6 User Guide
- ^ "A matrix having at least one dimension equal to zero is called an empty matrix", MATLAB Data Structures Archived 2009-12-28 at the Wayback Machine
- ^ Fudenberg & Tirole 1983, Section 1.1.1
- ^ Manning 1999, Section 15.3.4
- ^ Ward 1997, Ch. 2.8
- ^ Stinson 2005, Ch. 1.1.5 and 1.2.4
- ^ Association for Computing Machinery 1979, Ch. 7
- ^ Godsil & Royle 2004, Ch. 8.1
- ^ Punnen 2002
- ^ Lang 1987a, Ch. XVI.6
- ^ Nocedal 2006, Ch. 16
- ^ Lang 1987a, Ch. XVI.1
- ^ Lang 1987a, Ch. XVI.5. For a more advanced, and more general statement see Lang 1969, Ch. VI.2
- ^ Gilbarg & Trudinger 2001
- ^ Šolin 2005, Ch. 2.5. See also stiffness method.
- ^ Latouche & Ramaswami 1999
- ^ Mehata & Srinivasan 1978, Ch. 2.8
- ^ Healy, Michael (1986), Matrices for Statistics, Oxford University Press, ISBN978-0-19-850702-4
- ^ Krzanowski 1988, Ch. 2.2., p. 60
- ^ Krzanowski 1988, Ch. 4.1
- ^ Conrey 2007
- ^ Zabrodin, Brezin & Kazakov et al. 2006
- ^ Itzykson & Zuber 1980, Ch. 2
- ^ see Burgess & Moore 2007, section 1.6.3. (SU(3)), section 2.4.3.2. (Kobayashi–Maskawa matrix)
- ^ Schiff 1968, Ch. 6
- ^ Bohm 2001, sections II.4 and II.8
- ^ Weinberg 1995, Ch. 3
- ^ Wherrett 1987, part II
- ^ Riley, Hobson & Bence 1997, 7.17
- ^ Guenther 1990, Ch. 5
- ^ Shen, Crossley & Lun 1999 cited by Bretscher 2005, p. 1
- ^ a b c d e Discrete Mathematics 4th Ed. Dossey, Otto, Spense, Vanden Eynden, Published by Addison Wesley, October 10, 2001 ISBN 978-0-321-07912-1, p. 564-565
- ^ Needham, Joseph; Wang Ling (1959). Science and Civilisation in China. III. Cambridge: Cambridge University Press. p. 117. ISBN978-0-521-05801-8.
- ^ Discrete Mathematics 4th Ed. Dossey, Otto, Spense, Vanden Eynden, Published by Addison Wesley, October 10, 2001 ISBN 978-0-321-07912-1, p. 564
- ^ Merriam-Webster dictionary, Merriam-Webster, retrieved April 20, 2009
- ^ Although many sources state that J. J. Sylvester coined the mathematical term "matrix" in 1848, Sylvester published nothing in 1848. (For proof that Sylvester published nothing in 1848, see: J. J. Sylvester with H. F. Baker, ed., The Collected Mathematical Papers of James Joseph Sylvester (Cambridge, England: Cambridge University Press, 1904), vol. 1.) His earliest use of the term "matrix" occurs in 1850 in J. J. Sylvester (1850) "Additions to the articles in the September number of this journal, "On a new class of theorems," and on Pascal's theorem," The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science, 37: 363-370. From page 369: "For this purpose, we must commence, not with a square, but with an oblong arrangement of terms consisting, suppose, of m lines and n columns. This does not in itself represent a determinant, but is, as it were, a Matrix out of which we may form various systems of determinants ... "
- ^ The Collected Mathematical Papers of James Joseph Sylvester: 1837–1853, Paper 37, p. 247
- ^ Phil.Trans. 1858, vol.148, pp.17-37 Math. Papers II 475-496
- ^ Dieudonné, ed. 1978, Vol. 1, Ch. III, p. 96
- ^ Knobloch 1994
- ^ Hawkins 1975
- ^ Kronecker 1897
- ^ Weierstrass 1915, pp. 271–286
- ^ Bôcher 2004
- ^ Mehra & Rechenberg 1987
- ^ Whitehead, Alfred North; and Russell, Bertrand (1913) Principia Mathematica to *56, Cambridge at the University Press, Cambridge UK (republished 1962) cf page 162ff.
- ^ Tarski, Alfred; (1946) Introduction to Logic and the Methodology of Deductive Sciences, Dover Publications, Inc, New York NY, ISBN 0-486-28462-X.
References [edit]
- Anton, Howard (1987), Elementary Linear Algebra (5th ed.), New York: Wiley, ISBN0-471-84819-0
- Arnold, Vladimir I.; Cooke, Roger (1992), Ordinary differential equations, Berlin, DE; New York, NY: Springer-Verlag, ISBN978-3-540-54813-3
- Artin, Michael (1991), Algebra, Prentice Hall, ISBN978-0-89871-510-1
- Association for Computing Machinery (1979), Computer Graphics, Tata McGraw–Hill, ISBN978-0-07-059376-3
- Baker, Andrew J. (2003), Matrix Groups: An Introduction to Lie Group Theory , Berlin, DE; New York, NY: Springer-Verlag, ISBN978-1-85233-470-3
- Bau III, David; Trefethen, Lloyd N. (1997), Numerical linear algebra, Philadelphia, PA: Society for Industrial and Applied Mathematics, ISBN978-0-89871-361-9
- Beauregard, Raymond A.; Fraleigh, John B. (1973), A First Course In Linear Algebra: with Optional Introduction to Groups, Rings, and Fields , Boston: Houghton Mifflin Co., ISBN0-395-14017-X
- Bretscher, Otto (2005), Linear Algebra with Applications (3rd ed.), Prentice Hall
- Bronson, Richard (1970), Matrix Methods: An Introduction, New York: Academic Press, LCCN 70097490
- Bronson, Richard (1989), Schaum's outline of theory and problems of matrix operations, New York: McGraw–Hill, ISBN978-0-07-007978-6
- Brown, William C. (1991), Matrices and vector spaces , New York, NY: Marcel Dekker, ISBN978-0-8247-8419-5
- Coburn, Nathaniel (1955), Vector and tensor analysis, New York, NY: Macmillan, OCLC 1029828
- Conrey, J. Brian (2007), Ranks of elliptic curves and random matrix theory, Cambridge University Press, ISBN978-0-521-69964-8
- Fraleigh, John B. (1976), A First Course In Abstract Algebra (2nd ed.), Reading: Addison-Wesley, ISBN0-201-01984-1
- Fudenberg, Drew; Tirole, Jean (1983), Game Theory, MIT Press
- Gilbarg, David; Trudinger, Neil S. (2001), Elliptic partial differential equations of second order (2nd ed.), Berlin, DE; New York, NY: Springer-Verlag, ISBN978-3-540-41160-4
- Godsil, Chris; Royle, Gordon (2004), Algebraic Graph Theory, Graduate Texts in Mathematics, 207, Berlin, DE; New York, NY: Springer-Verlag, ISBN978-0-387-95220-8
- Golub, Gene H.; Van Loan, Charles F. (1996), Matrix Computations (3rd ed.), Johns Hopkins, ISBN978-0-8018-5414-9
- Greub, Werner Hildbert (1975), Linear algebra, Graduate Texts in Mathematics, Berlin, DE; New York, NY: Springer-Verlag, ISBN978-0-387-90110-7
- Halmos, Paul Richard (1982), A Hilbert space problem book, Graduate Texts in Mathematics, 19 (2nd ed.), Berlin, DE; New York, NY: Springer-Verlag, ISBN978-0-387-90685-0, MR 0675952
- Horn, Roger A.; Johnson, Charles R. (1985), Matrix Analysis, Cambridge University Press, ISBN978-0-521-38632-6
- Householder, Alston S. (1975), The theory of matrices in numerical analysis, New York, NY: Dover Publications, MR 0378371
- Kreyszig, Erwin (1972), Advanced Engineering Mathematics (3rd ed.), New York: Wiley, ISBN0-471-50728-8 .
- Krzanowski, Wojtek J. (1988), Principles of multivariate analysis, Oxford Statistical Science Series, 3, The Clarendon Press Oxford University Press, ISBN978-0-19-852211-9, MR 0969370
- Itô, Kiyosi, ed. (1987), Encyclopedic dictionary of mathematics. Vol. I-IV (2nd ed.), MIT Press, ISBN978-0-262-09026-1, MR 0901762
- Lang, Serge (1969), Analysis II, Addison-Wesley
- Lang, Serge (1987a), Calculus of several variables (3rd ed.), Berlin, DE; New York, NY: Springer-Verlag, ISBN978-0-387-96405-8
- Lang, Serge (1987b), Linear algebra, Berlin, DE; New York, NY: Springer-Verlag, ISBN978-0-387-96412-6
- Lang, Serge (2002), Algebra, Graduate Texts in Mathematics, 211 (Revised third ed.), New York: Springer-Verlag, ISBN978-0-387-95385-4, MR 1878556
- Latouche, Guy; Ramaswami, Vaidyanathan (1999), Introduction to matrix analytic methods in stochastic modeling (1st ed.), Philadelphia, PA: Society for Industrial and Applied Mathematics, ISBN978-0-89871-425-8
- Manning, Christopher D.; Schütze, Hinrich (1999), Foundations of statistical natural language processing, MIT Press, ISBN978-0-262-13360-9
- Mehata, K. M.; Srinivasan, S. K. (1978), Stochastic processes, New York, NY: McGraw–Hill, ISBN978-0-07-096612-3
- Mirsky, Leonid (1990), An Introduction to Linear Algebra, Courier Dover Publications, ISBN978-0-486-66434-7
- Nering, Evar D. (1970), Linear Algebra and Matrix Theory (2nd ed.), New York: Wiley, LCCN 76-91646
- Nocedal, Jorge; Wright, Stephen J. (2006), Numerical Optimization (2nd ed.), Berlin, DE; New York, NY: Springer-Verlag, p. 449, ISBN978-0-387-30303-1
- Oualline, Steve (2003), Practical C++ programming, O'Reilly, ISBN978-0-596-00419-4
- Press, William H.; Flannery, Brian P.; Teukolsky, Saul A.; Vetterling, William T. (1992), "LU Decomposition and Its Applications" (PDF), Numerical Recipes in FORTRAN: The Art of Scientific Computing (2nd ed.), Cambridge University Press, pp. 34–42, archived from the original on 2009-09-06 CS1 maint: unfit URL (link)
- Protter, Murray H.; Morrey, Jr., Charles B. (1970), College Calculus with Analytic Geometry (2nd ed.), Reading: Addison-Wesley, LCCN 76087042
- Punnen, Abraham P.; Gutin, Gregory (2002), The traveling salesman problem and its variations, Boston, MA: Kluwer Academic Publishers, ISBN978-1-4020-0664-7
- Reichl, Linda E. (2004), The transition to chaos: conservative classical systems and quantum manifestations, Berlin, DE; New York, NY: Springer-Verlag, ISBN978-0-387-98788-0
- Rowen, Louis Halle (2008), Graduate Algebra: noncommutative view, Providence, RI: American Mathematical Society, ISBN978-0-8218-4153-2
- Šolin, Pavel (2005), Partial Differential Equations and the Finite Element Method, Wiley-Interscience, ISBN978-0-471-76409-0
- Stinson, Douglas R. (2005), Cryptography, Discrete Mathematics and its Applications, Chapman & Hall/CRC, ISBN978-1-58488-508-5
- Stoer, Josef; Bulirsch, Roland (2002), Introduction to Numerical Analysis (3rd ed.), Berlin, DE; New York, NY: Springer-Verlag, ISBN978-0-387-95452-3
- Ward, J. P. (1997), Quaternions and Cayley numbers , Mathematics and its Applications, 403, Dordrecht, NL: Kluwer Academic Publishers Group, doi:10.1007/978-94-011-5768-1, ISBN978-0-7923-4513-8, MR 1458894
- Wolfram, Stephen (2003), The Mathematica Book (5th ed.), Champaign, IL: Wolfram Media, ISBN978-1-57955-022-6
Physics references [edit]
- Bohm, Arno (2001), Quantum Mechanics: Foundations and Applications, Springer, ISBN0-387-95330-2
- Burgess, Cliff; Moore, Guy (2007), The Standard Model. A Primer, Cambridge University Press, ISBN978-0-521-86036-9
- Guenther, Robert D. (1990), Modern Optics, John Wiley, ISBN0-471-60538-7
- Itzykson, Claude; Zuber, Jean-Bernard (1980), Quantum Field Theory , McGraw–Hill, ISBN0-07-032071-3
- Riley, Kenneth F.; Hobson, Michael P.; Bence, Stephen J. (1997), Mathematical methods for physics and engineering, Cambridge University Press, ISBN0-521-55506-X
- Schiff, Leonard I. (1968), Quantum Mechanics (3rd ed.), McGraw–Hill
- Weinberg, Steven (1995), The Quantum Theory of Fields. Volume I: Foundations, Cambridge University Press, ISBN0-521-55001-7
- Wherrett, Brian S. (1987), Group Theory for Atoms, Molecules and Solids, Prentice–Hall International, ISBN0-13-365461-3
- Zabrodin, Anton; Brezin, Édouard; Kazakov, Vladimir; Serban, Didina; Wiegmann, Paul (2006), Applications of Random Matrices in Physics (NATO Science Series II: Mathematics, Physics and Chemistry), Berlin, DE; New York, NY: Springer-Verlag, ISBN978-1-4020-4530-1
Historical references [edit]
- A. Cayley A memoir on the theory of matrices. Phil. Trans. 148 1858 17-37; Math. Papers II 475-496
- Bôcher, Maxime (2004), Introduction to higher algebra, New York, NY: Dover Publications, ISBN978-0-486-49570-5 , reprint of the 1907 original edition
- Cayley, Arthur (1889), The collected mathematical papers of Arthur Cayley, I (1841–1853), Cambridge University Press, pp. 123–126
- Dieudonné, Jean, ed. (1978), Abrégé d'histoire des mathématiques 1700-1900, Paris, FR: Hermann
- Hawkins, Thomas (1975), "Cauchy and the spectral theory of matrices", Historia Mathematica, 2: 1–29, doi:10.1016/0315-0860(75)90032-4, ISSN 0315-0860, MR 0469635
- Knobloch, Eberhard (1994), "From Gauss to Weierstrass: determinant theory and its historical evaluations", The intersection of history and mathematics, Science Networks Historical Studies, 15, Basel, Boston, Berlin: Birkhäuser, pp. 51–66, MR 1308079
- Kronecker, Leopold (1897), Hensel, Kurt (ed.), Leopold Kronecker's Werke, Teubner
- Mehra, Jagdish; Rechenberg, Helmut (1987), The Historical Development of Quantum Theory (1st ed.), Berlin, DE; New York, NY: Springer-Verlag, ISBN978-0-387-96284-9
- Shen, Kangshen; Crossley, John N.; Lun, Anthony Wah-Cheung (1999), Nine Chapters of the Mathematical Art, Companion and Commentary (2nd ed.), Oxford University Press, ISBN978-0-19-853936-0
- Weierstrass, Karl (1915), Collected works, 3
Further reading [edit]
- "Matrix", Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- Kaw, Autar K. (September 2008), Introduction to Matrix Algebra, ISBN978-0-615-25126-4
- The Matrix Cookbook (PDF) , retrieved 24 March 2014
- Brookes, Mike (2005), The Matrix Reference Manual, London: Imperial College, retrieved 10 Dec 2008
External links [edit]
- MacTutor: Matrices and determinants
- Matrices and Linear Algebra on the Earliest Uses Pages
- Earliest Uses of Symbols for Matrices and Vectors
Discrete Mathematics With Applications 4th Edition Chapter Overview
Source: https://en.wikipedia.org/wiki/Matrix_(mathematics)
0 Response to "Discrete Mathematics With Applications 4th Edition Chapter Overview"
Post a Comment